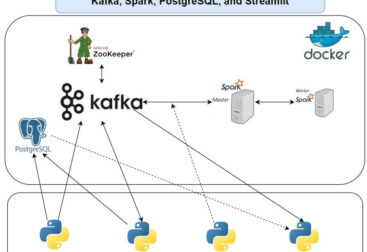
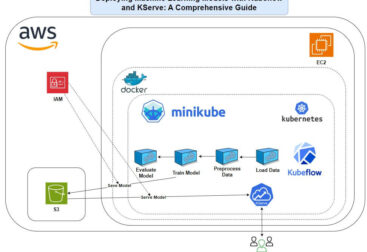
Summary
- Selected as one of 81 fellowship recipients from over 3,000 applicants for the KaggleX fellowship program.
- Final project ReguGuard AI selected as one of the 16 final showcases in the end of program celebration - Presentation Video, PPT (Links to codes and models)
- Built an AI chatbot ReguGuard answering financial risk compliance questions by fine-tuning Gemma-2b and Gemma-7b LLMs.
- The best finetuned model, https://huggingface.co/shijunju/gemma_7b_finRisk_r6_4VersionQ, achieved accuracy rate of 78.6%.
- Tested effects of model sizes (2b vs 7b), number of versions of similar questions (3 vs 4), LoRA rank sizes (6 vs 10), and beam search of 3.
- Adapted LLamaIndex's RAFT DatasetPack module and used OpenAI API to generate over 14,000 question-answer pairs for training
Skills: Fine Tuning · Large Language Models (LLM) · Natural Language Processing (NLP) · TPU · GPU · Artificial Intelligence (AI) · LoRA · QLoRA · FinTech · financial risk compliance · Chatbot Development · Keras · PyTorch · Project Management · Gemma-2b · Gemma-7b · Data Cleaning · Synthetic Data Generation
Highlights




Project Links and Codes
Data
●Notebook for data generation: https://www.kaggle.com/code/shijunju/raft-data-generation
●https://huggingface.co/datasets/shijunju/fincen_all_questions_5versions
Finetuned Gemma-2b: full model
●Finetuning Kaggle Notebook: https://www.kaggle.com/code/shijunju/finetune-gemma-2b-with-quantization-using-lora
●https://huggingface.co/shijunju/gemma_2b_finRisk
Finetuned Gemma-7b: LoRA adaptor files only
●Finetuning Kaggle Notebook: https://www.kaggle.com/code/shijunju/tpu-keras-gemma-distributed-finetuning-gemma-7b
●LoRA Rank 6, 4-version-question training (most accurate 78.6%): https://huggingface.co/shijunju/gemma_7b_finRisk_r6_4VersionQ
●LoRA Rank 10, 4-version-question training: https://huggingface.co/shijunju/gemma_7b_finRisk_r10_4VersionQ
●LoRA Rank 6, 3-version-question training: https://huggingface.co/shijunju/gemma_7b_finRisk_r6_3VersionQ
Training / Experiment notes
●https://docs.google.com/spreadsheets/d/1iFz_1qFsGXXOi0ooO2zJgQxMxrIqK2dxDOBZp_AmTlE/edit?usp=sharing
References: TPU Training
●https://www.kaggle.com/code/nilaychauhan/keras-gemma-distributed-finetuning-and-inference