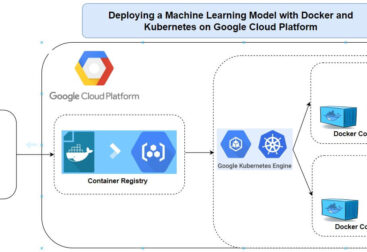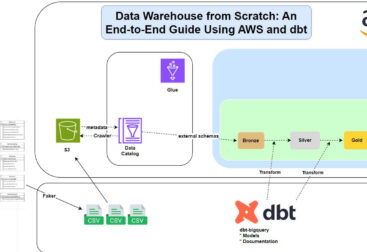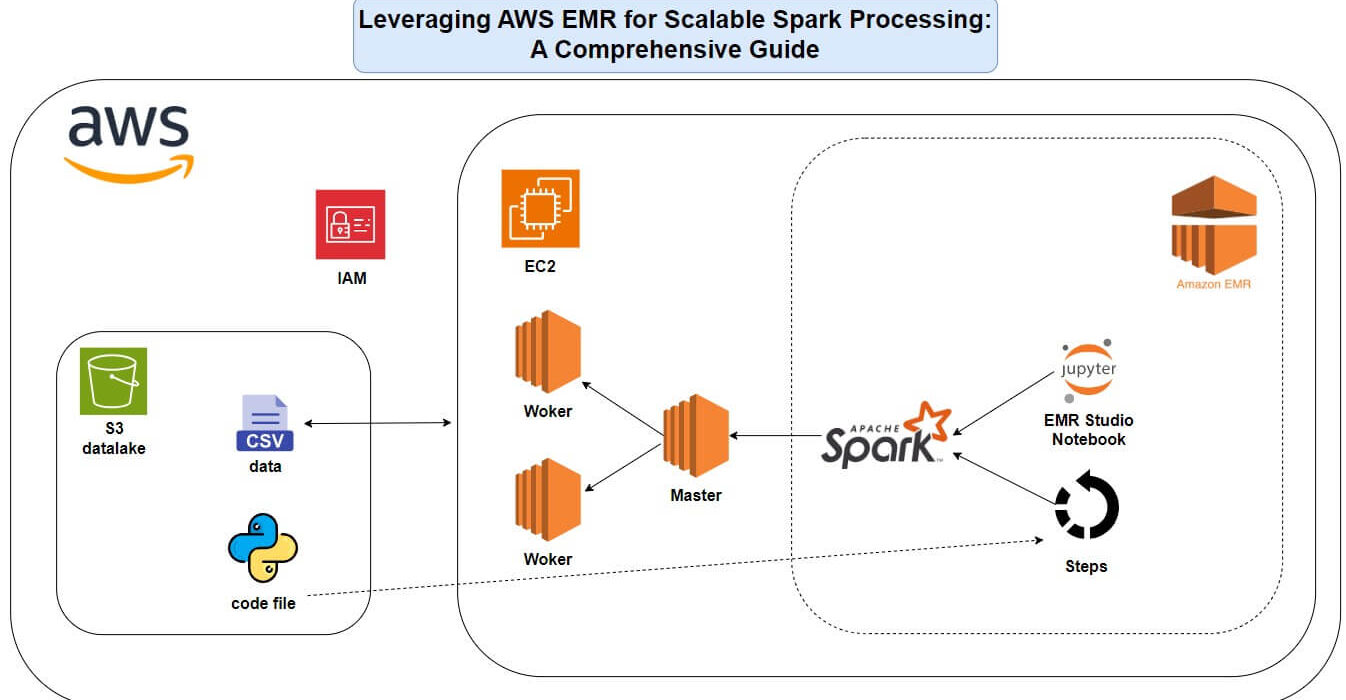
This repo shows how to use AWS EMR and Apache Spark to process big data in the cloud. It includes scripts and notes from my Medium guide on setting up and running Spark jobs.
Key Features
- Cluster Setup: Configured EMR with IAM, VPCs, and S3.
- Spark Jobs: PySpark scripts for interactive (EMR Studio) and automated (EMR Steps) processing.
Tech Stack
Link: Read the full article on Medium
Code: https://github.com/shj37/AWS-EMR-Scalable-Spark-Processing