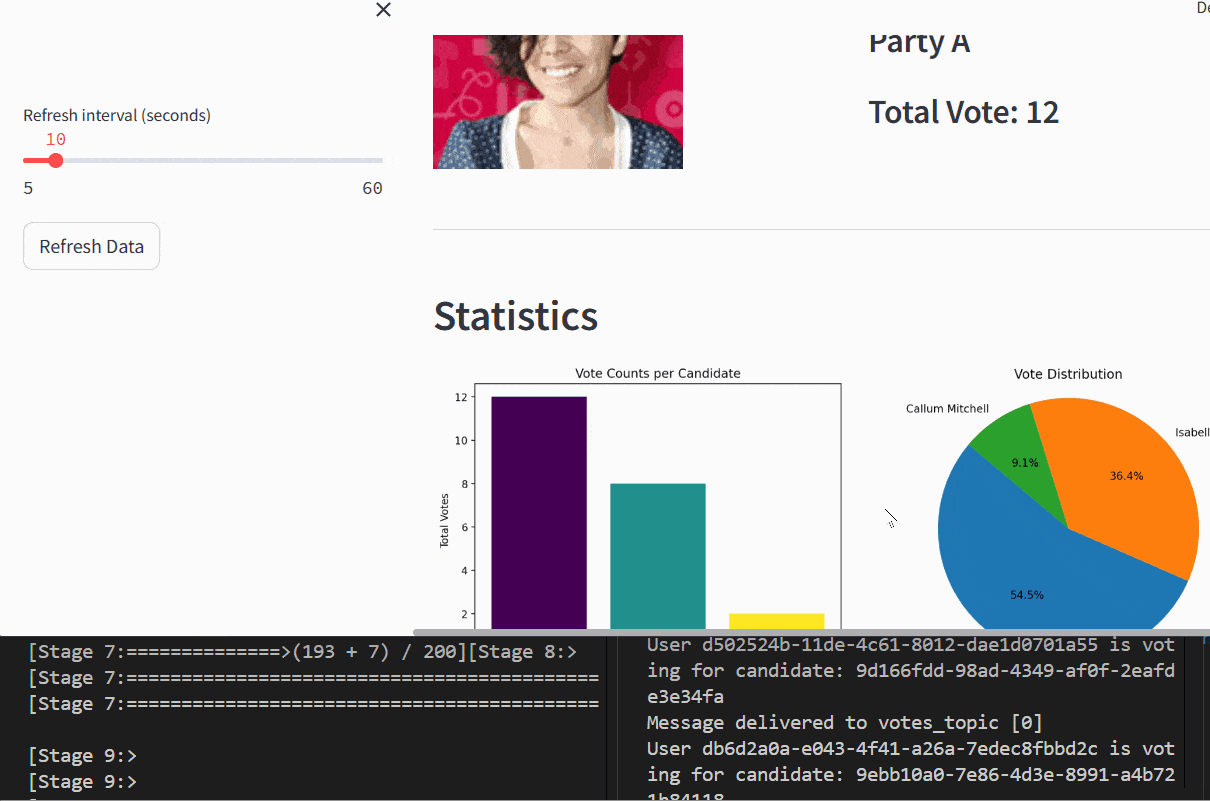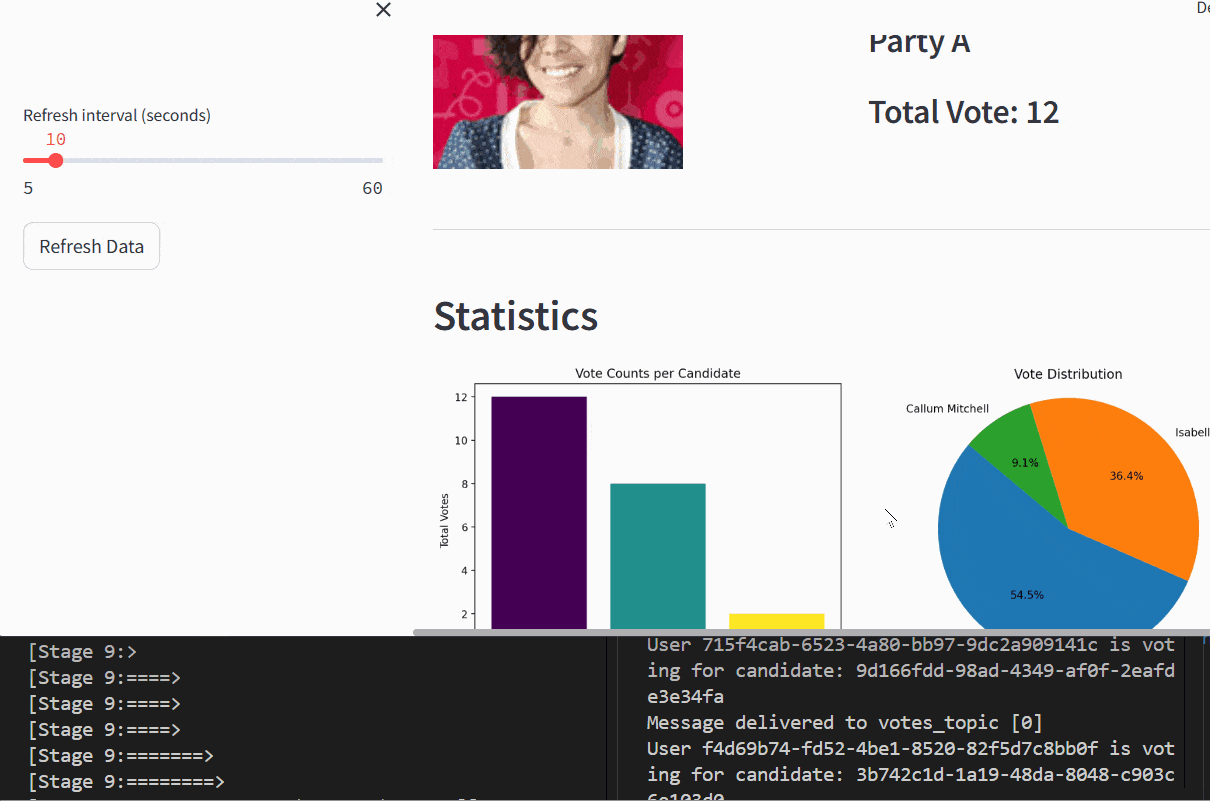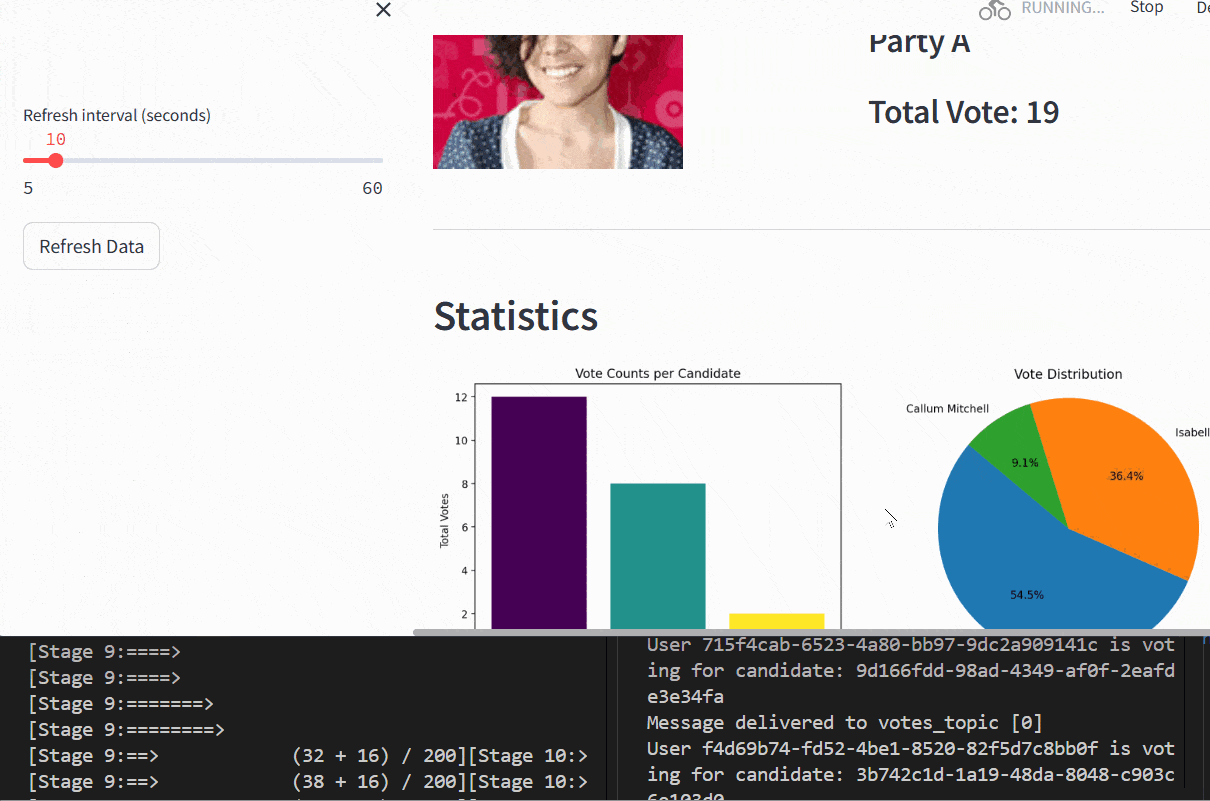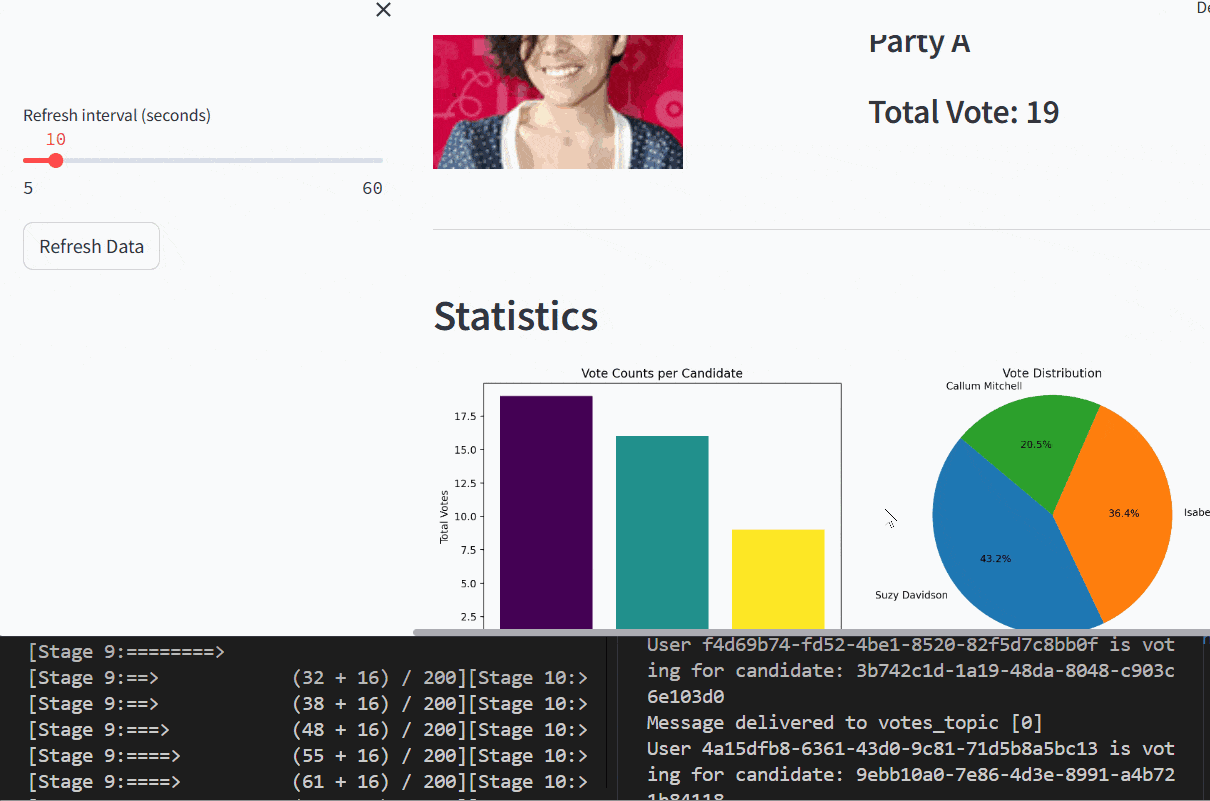
This project involves the development of a real-time analytics dashboard designed to process and visualize voting data for an election simulation involving three political parties: Party A, Party B, and Party C. The system integrates multiple technologies to handle data streaming, processing, and visualization, demonstrating proficiency in modern data engineering tools. For a detailed overview, refer to the full article here.
Project Overview and Technical Contributions:
- Objective: Built an end-to-end data pipeline to simulate an election with 250 voters and three candidates, processing and visualizing voting data in real time.
- Technologies Used:
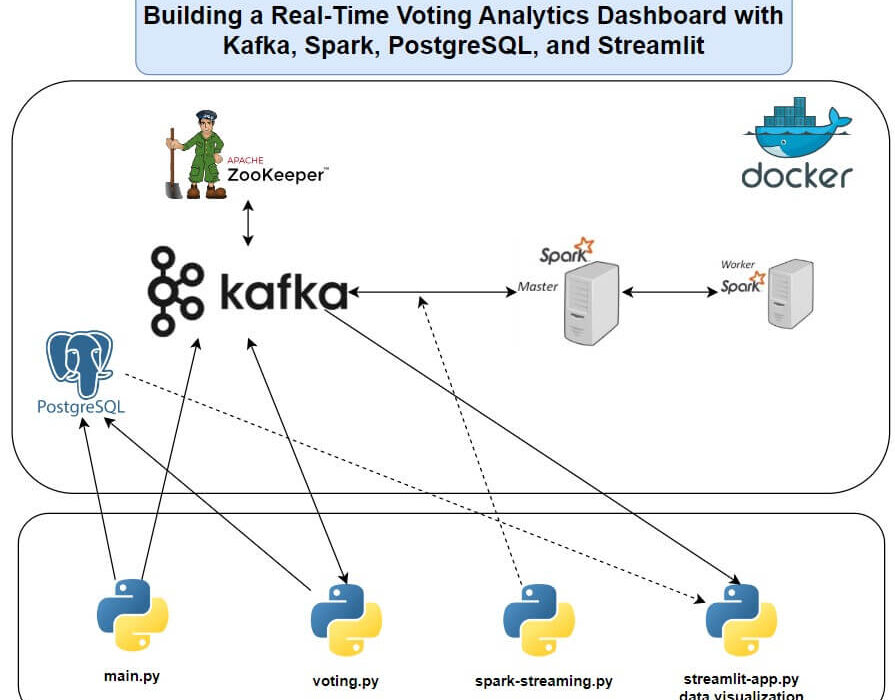
- Apache Kafka: Managed real-time data streaming for voter registrations and votes, ensuring scalable and fault-tolerant data flow.
- Apache Spark: Processed streaming data with Spark Streaming, performing aggregations such as votes per candidate and turnout by location.
- PostgreSQL: Stored static data (candidate and voter profiles) and dynamic vote data, leveraging relational database capabilities for structured storage.
- Streamlit: Developed an interactive dashboard to display key metrics, including leading candidates and vote distribution, with dynamic visualizations.
- Docker Compose: Orchestrated services (Zookeeper, Kafka Broker, PostgreSQL, Spark Master, and Worker) for a reproducible and isolated environment.
- Key Implementation Details:
- Configured a Python virtual environment to ensure dependency isolation and reproducibility.
- Designed a Spark Streaming script (spark-streaming.py) to read from Kafka topics, process data using a defined schema, and write aggregated results back to Kafka.
- Utilized PostgreSQL JDBC driver for seamless integration with Spark, enabling data persistence.
- Created a Streamlit dashboard to present real-time insights, including vote counts and geographic turnout, enhancing accessibility for stakeholders.
- Outcomes:
- Successfully demonstrated real-time data processing and visualization, handling dynamic election data with low latency.
- Ensured system scalability and reliability through containerized services and robust streaming architecture.
- Skills Demonstrated:
- Expertise in real-time data pipelines and streaming technologies (Kafka, Spark Streaming).
- Proficiency in database management and integration (PostgreSQL, JDBC).
- Competence in building interactive data visualizations with Streamlit.
- Strong understanding of containerization and service orchestration using Docker Compose.
This project highlights the ability to design and implement a scalable, real-time data engineering solution, integrating multiple tools to deliver actionable insights. For further details, see the full article on Medium.