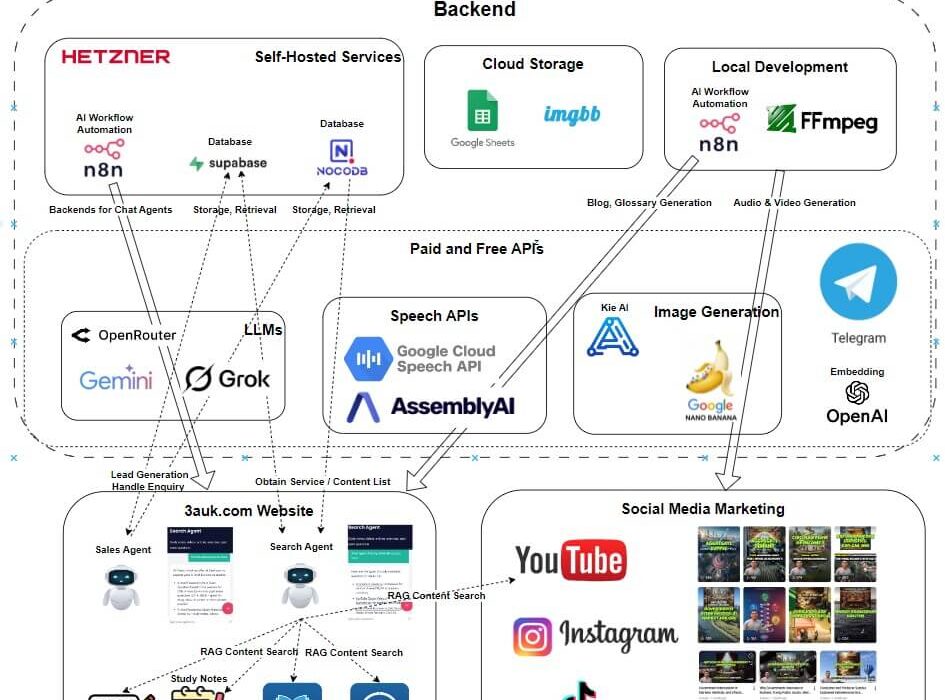
An end-to-end system for generating, organizing, and delivering educational content using modern AI tools — covering text, images, audio, and video production, alongside intelligent assistants for content retrieval and lead capture.
- AI Agents (Search and Sales) https://3auk.com (or any page on the website)
- List of Blogs: 3auk.com/blog
- Glossary List: 3auk.com/glossary-3
- Study Videos 16:9 https://www.youtube.com/@3aukcom/videos
- 9:16 portrait study videos https://www.tiktok.com/@3aukcom
What the System Does
- Generates educational blog articles, glossary entries, study notes, and conversation scripts using LLMs
- Produces illustrative images and analytical graphs (via AI-generated LaTeX) for educational use
- Converts scripts to audio and assembles short educational videos with synchronized subtitles
- Organizes all content assets in structured databases with rich metadata for retrieval and reuse
- Serves a RAG-powered search agent that helps students find relevant content by meaning, not just keywords
- Runs a conversational lead generation agent that captures visitor information into a CRM table
Technical Stack
| Layer | Tools |
|---|---|
| Workflow orchestration | n8n (self-hosted, Hetzner) |
| LLMs | Gemini 2.5 Flash, Grok 4.1 Fast, Perplexity API |
| Text-to-speech | Google Cloud TTS, Kokoro TTS |
| Speech-to-text / transcription | AssemblyAI |
| Image generation | Nano Banana Pro, kie.ai |
| Video and media processing | FFmpeg |
| Structured data & agent tables | NocoDB (self-hosted) |
| Vector store & interaction logs | Supabase (PostgreSQL, self-hosted) |
| Embeddings | OpenAI Embedding API |
| Image hosting | imgbb.com |
| File storage | Google Drive, Google Sheets |
Architecture Highlights
Cost-optimized by design. Fast/Mini-tier LLMs (Gemini 2.5 Flash, Grok 4.1 Fast) are used for bulk generation; more capable models are brought in selectively where quality demands it. NocoDB and n8n are self-hosted on Hetzner to reduce running costs versus managed SaaS equivalents.
Checkpoint-based logging throughout. Every pipeline stage logs intermediate outputs — article outlines, audio files, transcripts, image prompts — so that workflow failures can be resumed from the last successful step rather than restarted from scratch. This is practical necessity at API-call scale.
Asset reuse built into the data model. Scripts, audio, images, and transcripts are catalogued with metadata in NocoDB so they can be repurposed across contexts — for example, the same source assets generate both a vertical (9:16) and horizontal (16:9) video without any regeneration.
RAG search pipeline: Content summaries are embedded using OpenAI's embedding API and stored as vectors in Supabase. On query, similarity search retrieves the top matching documents, which an LLM synthesizes into a direct answer with links. Smaller structured datasets (e.g. service listings) are kept in NocoDB and accessed via API directly, skipping the vector layer where it adds unnecessary overhead.
Human-in-the-loop at the right points. A single review checkpoint after the AI produces a draft outline catches structural problems before full generation proceeds. Conversation script quality and image selection also involve human review — areas where current fast models produce the most errors.
What Is and Isn’t Automated
| Stage | Status |
|---|---|
| Article generation | Largely automated — one human review of the draft outline |
| Audio generation | Largely automated — human review of conversation scripts |
| Image generation (illustrative) | Partial — model handles generation; human curates and selects |
| Analytical graph generation | Partial — LLM generates LaTeX code; human compiles and adjusts |
| Video assembly | Largely automated via FFmpeg |
| Subtitle segmentation | Requires significant human correction — current models are unreliable on videos over ~2 minutes |
| Search agent (RAG) | Automated after initial content indexing |
| Lead generation agent | Automated; guardrails filter off-topic inputs |
Video subtitle segmentation is the primary remaining bottleneck. Intelligently grouping word-level timestamps into phrase-coherent subtitle segments — respecting domain-specific terminology across a full transcript — exceeds what current fast models handle reliably.
Key Design Decisions
- n8n over custom code for workflow orchestration — visual pipelines are easier to debug, modify, and hand off than bespoke scripts, and n8n's self-hosted option keeps costs low.
- NocoDB over Airtable — functionally comparable for this use case at significantly lower cost when self-hosted.
- AssemblyAI for transcription — chosen for word-level timestamp accuracy and a free quota sufficient for this project's volume.
- Google Cloud TTS over ElevenLabs — ElevenLabs' higher-quality voices are restricted to paid tiers; Google's free quota covers the project's needs. Kokoro TTS is a noted open-source alternative for CPU-only local inference.
- Analytical graphs via LaTeX, not image models — current image generation models produce unreliable geometry and label placement for logical/mathematical diagrams; code-based generation is more precise and reproducible.
Read the full article: Building an AI-Powered Educational Content Pipeline: From Text to Video, with Intelligent Assistants | by Shijun Ju | Feb, 2026 | Medium


