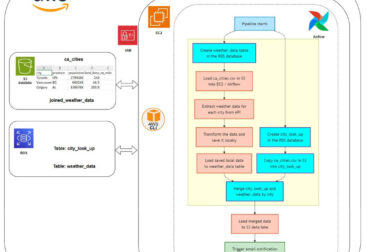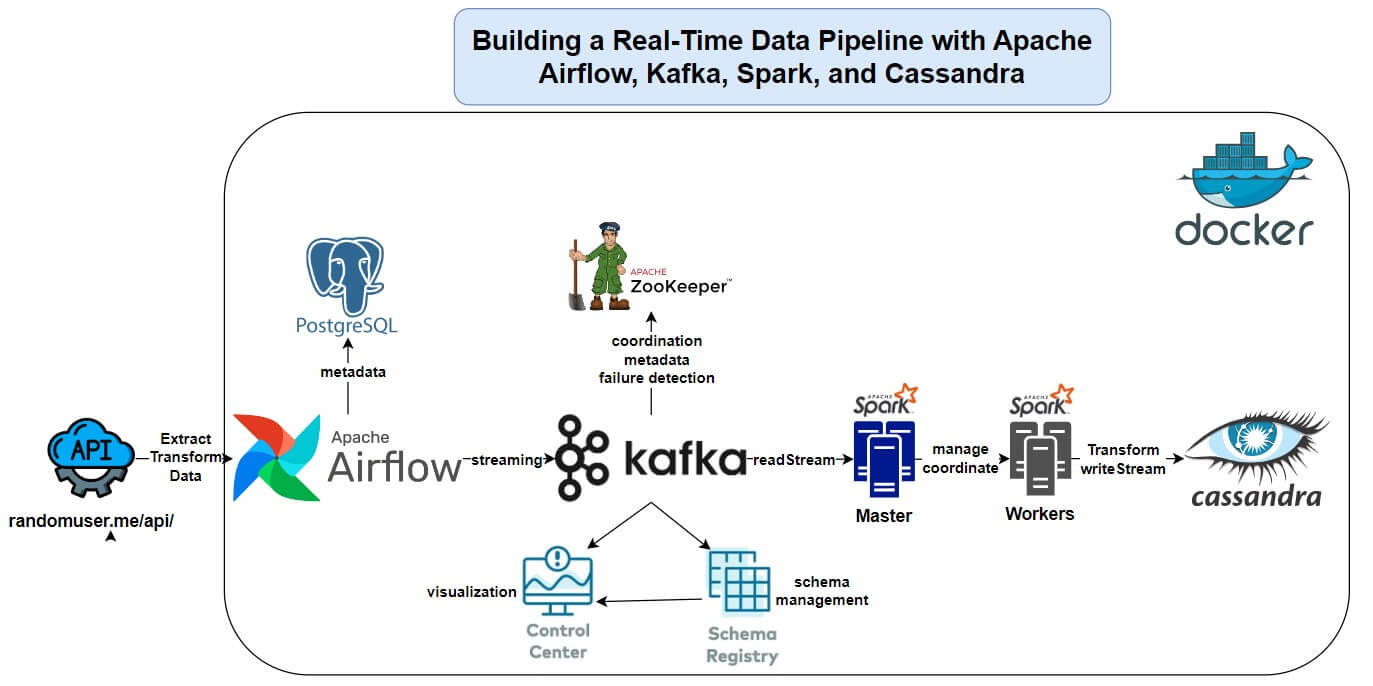
This project is a real-time data pipeline that pulls data from an external API, processes it with Apache Kafka and Spark, and stores it in Apache Cassandra. Apache Airflow handles the scheduling, and Docker ties it all together for a clean, reproducible setup.
Details:
- Data Flow: Streams data from an API into Kafka, processes it with Spark in real-time, and saves it to Cassandra.
- Automation: Airflow DAG runs daily, streaming data for 1 minute per cycle.
- Setup: Docker Compose launches Kafka, Spark, Cassandra, and Airflow in one go.
- Tech Stack: Apache Airflow, Kafka, Spark, Cassandra, Docker, Python.
What I Learned:
I got practical experience with real-time data tools, from ingestion to storage, and figured out how to make everything work together smoothly in a containerized environment. It’s a solid example of what I can do with data engineering.
Link: Read the full article on Medium
Code: https://github.com/shj37/Real-Time-Pipeline-Airflow-Kafka-Spark-Cassandra